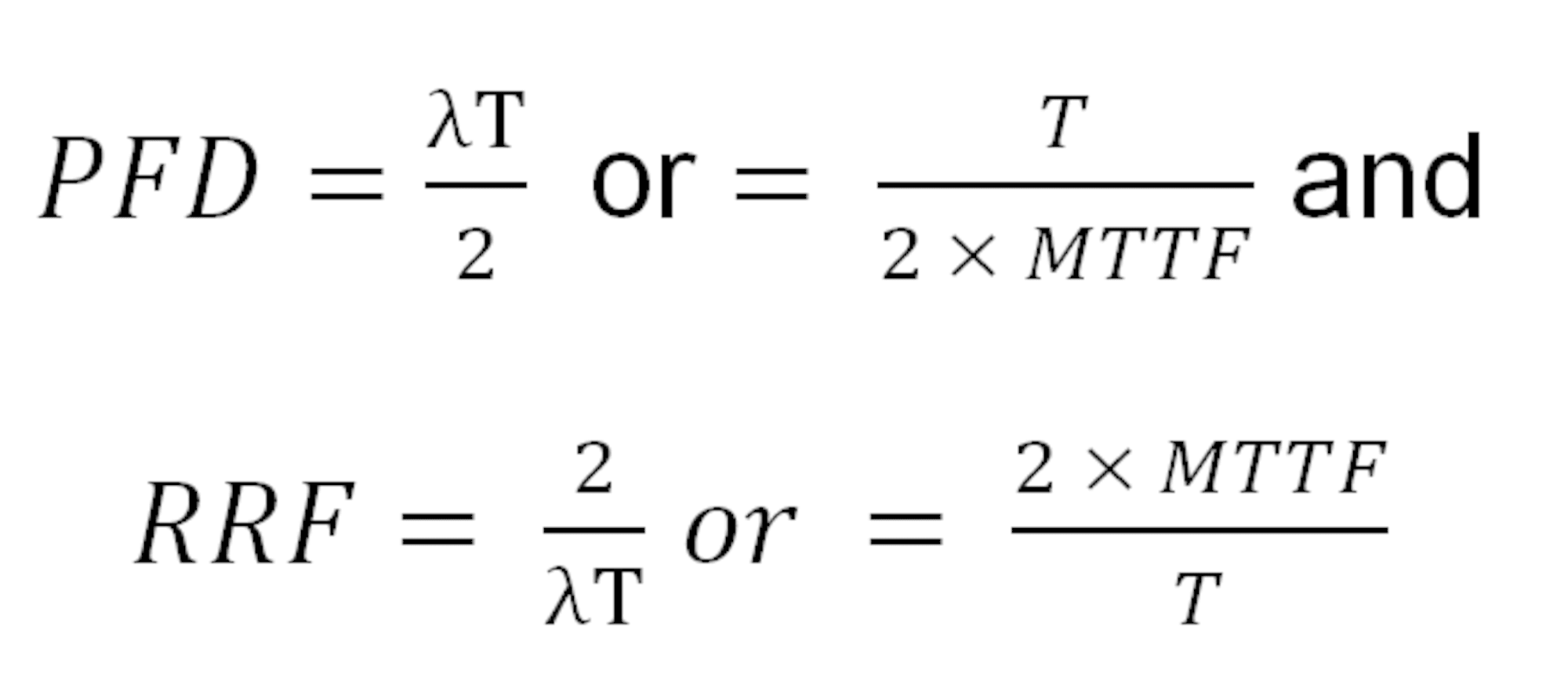how to ensure critical element dependability?
Any structure, plant, equipment, system (including computer software) or component part whose failure could cause or contribute substantially to a major accident is Safety Critical, as is any that is intended to prevent or limit the consequences of a major accident. In new ventures, Safety Critical Elements (SCEs) are identified as part of the Hazard Assessment process. On older plant, there may be a need to reconfirm the safety premises that were established during the original project and Process Hazard Reviews (PHRs) should be revisited on a regular basis (at least once every five years) to confirm that there has been no change to the hazard or risk.
SCE identification includes elements that participate in the detection, control and mitigation of major accidents. Confirming SCE activity requires a system-by-system approach, because some components may have this exposure and others may not. Some failures may not directly initiate a major accident, but could make a significant contribution to a chain of events that could result in a major accident – these are also SCEs.
Developing the risk profile for an asset ensures that focus is given to identifying hazards, assessing risks adequately and identifying risk control/ mitigation measures.
Riser emergency shutdown valves (RESDVs) are an essential hazard reduction measure for offshore
installations; they are part of an offshore facility’s gamut of protective systems designed to ensure safe operation and they are SCEs. RESDVs are also a legal requirement under the UK Pipelines Safety Regulations 1996, which also require that the valves shall be maintained “in an efficient state, in efficient working order and in good repair”. In the UK, failure of a safety critical element such as an RESDV, whether deriving from test results or failure on demand, is defined as a dangerous occurrence and must be reported.
The Health and Safety Laboratory (HSL) issued a report11 through the UK Health and Safety Executive (HSE) in November 2015 covering “Investigations into the immediate and underlying causes of failure of offshore riser emergency shutdown valves”12. This information is licensed under the terms of the Open Government Licence13.
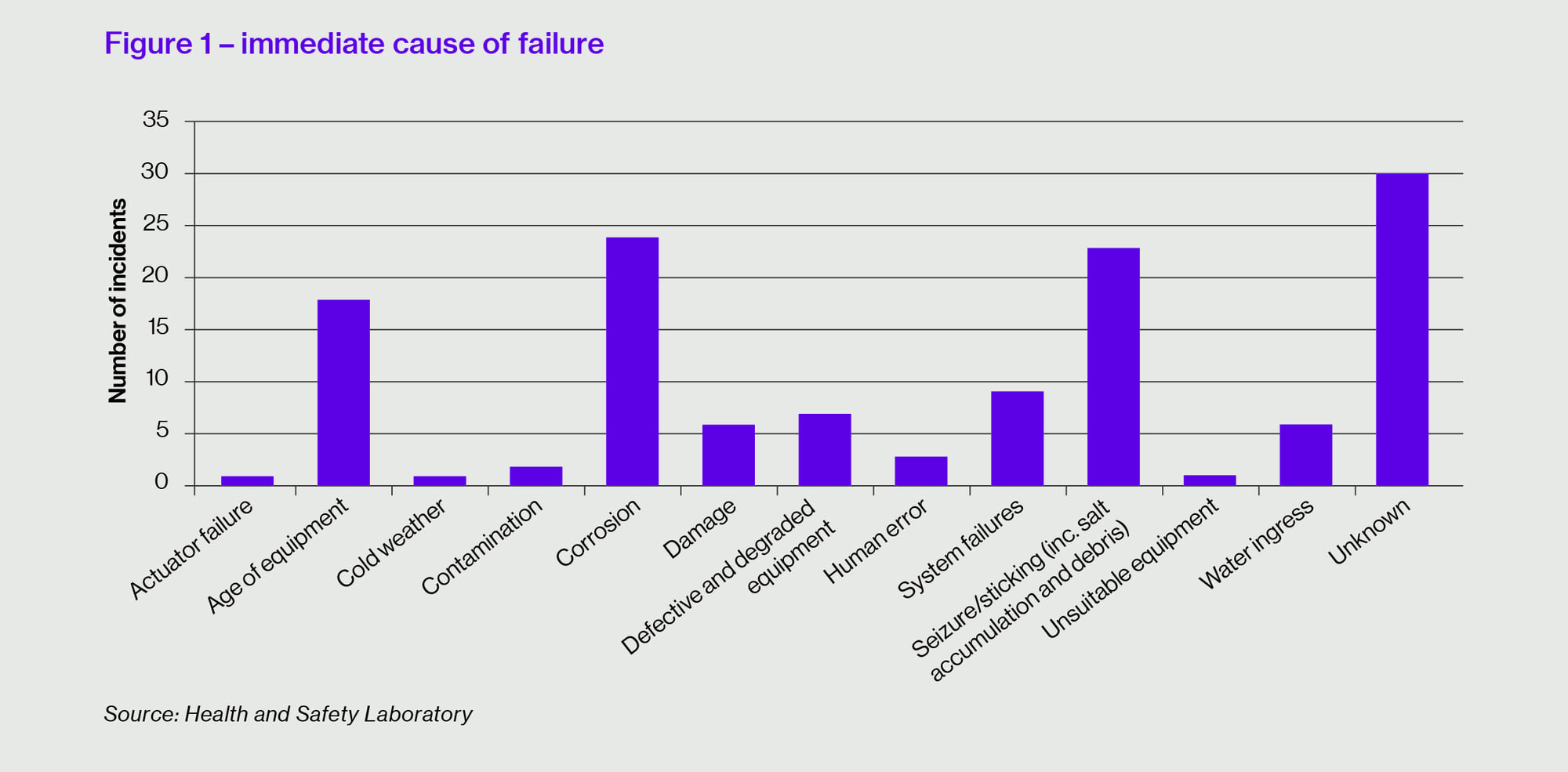
Over a seven-year period to March 2014, the study revealed that some 180 RESDVs failed. (Reporting was sparse until mid-2009, so most of the failures happened over a four to five year period.)
11 RR1072 12 http://www.hse.gov.uk/research/rrpdf/rr1072.pdf 13 http://www.nationalarchives.gov.uk/doc/open-government-licence 14See http://www.psa.no/getfile.php/PDF/RNNP_2013/Trends%20summary%202013.pdf
Two thirds of the failures occurred during testing, which supports the importance of this activity. Considering the sample size, this represented a failure-on-test rate of around 1.2%, which is similar to the Norwegian Continental Shelf failure-on-test rate of 2.0% over a similar period14. Although the North Sea environment is harsh when compared to many offshore locations, common mode weaknesses are clearly applicable elsewhere.
Figure 1 above shows the immediate failure causes of the HSL review summarised into several groupings to help with interpretation.
The majority of the tested valves had been in service for more than 20 years and although age has been defined as one of the failure causes, this merits further analysis because a well-maintained valve should function well, independent of its age. The contrary suggests that maintenance is not achieving its purpose.
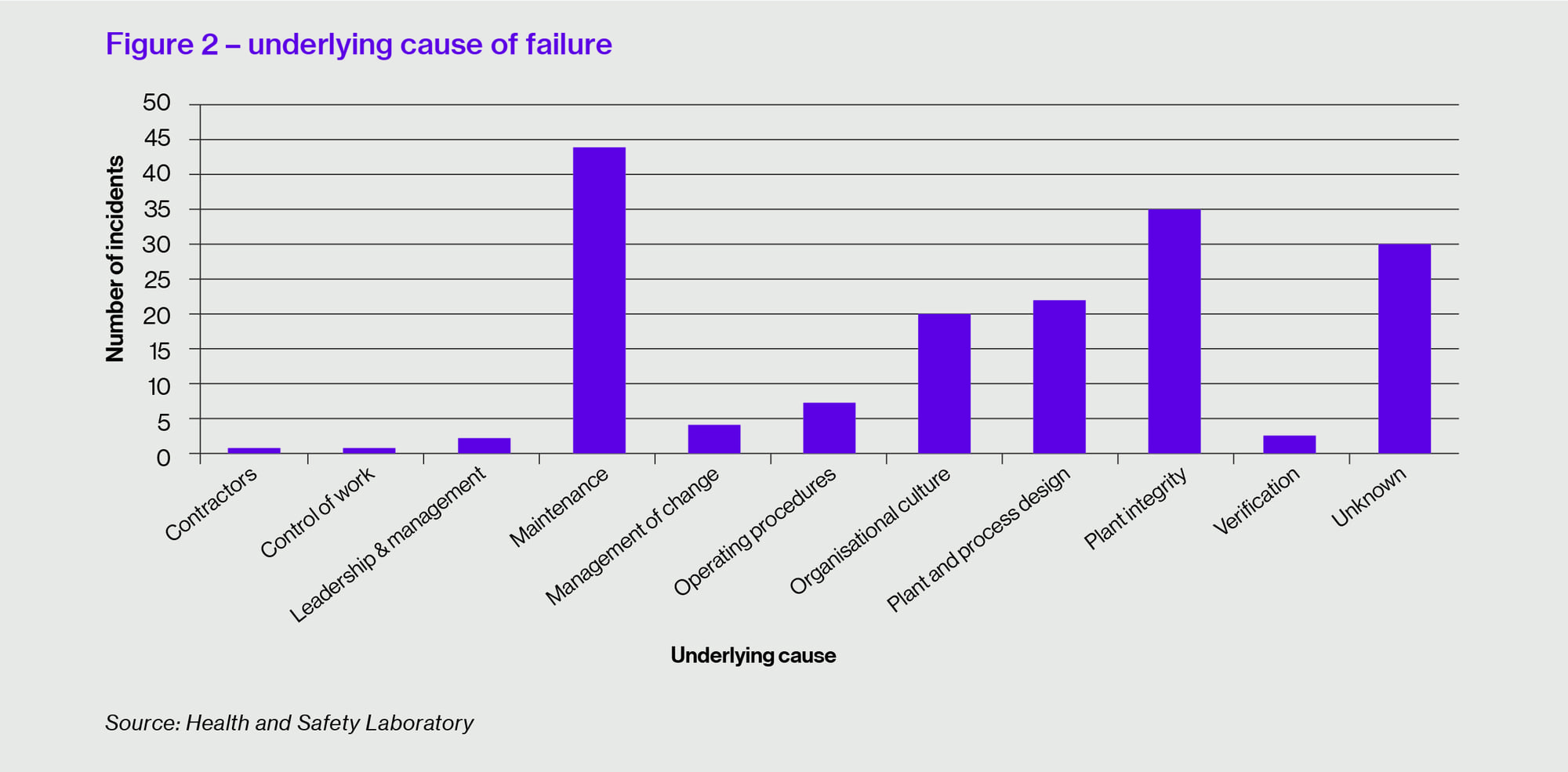
Figure 2 above provides some further analysis on the underlying cause of the failures and suggests that maintenance is a primary factor, followed by plant integrity, plant and process design, and organisational culture. (These and other headings were developed by the HSL to help identify the underlying causes of incidents; further information is included in RR 1072.)
Any control system can fail, but the underlying problem referred to in organisational culture is a lack of learning from previous failures – part of the corporate amnesia often referred to in safety circles. Proper maintenance and regular proof testing of RESDVs make a major contribution to maintaining safety integrity. It is clear that data recall and trending, as part of a good reliability-centred maintenance (RCM) programme, are essential to avoid failures, but too often the required feedback is missing.
RESDV failure mechanisms include:
Operators need to record relevant measurable quantities, which for RESDVs includes failure closure times and internal leakage rates, analyse the results and feed these back into the preventive maintenance programme. The unsupported “pass” or “fail” comment does not hold water in an analytical maintenance programme.
Having identified that RESDVs are SCEs and that they have a failure rate that exposes their platforms to a potentially unacceptable risk, what steps are necessary to avoid that the valve is present in a potentially failed state? This falls clearly into the regime of analytical maintenance where conditions are monitored on-line where possible and inspected/tested as necessary to provide a full performance profile.
The point of testing is to verify, so far as reasonably practicable, that each sensing device and related final element will respond within defined test tolerances so that the control circuit performs its shutdown function as specified, i.e. to tease out the offending failed elements. Depending on guideline interpretation, user experience and maintenance sophistication, there are different inspection/ testing regimes in place for RESDVs; some of these are defensible, others less so.
Proof testing should be done:
To define the scheduled test programme requires an understanding of the element’s integrity or dependability. The concept of analysing the performance of safety functions was an extension of Hazard and Operability studies in the 1970s; however, their Probable Failure on Demand (PFD) estimates were questionable because of unreliable data related to equipment and system failure. A more mature industry that has also evoked changed attitudes towards discussing losses now provides engineers with more reliable numbers.
BS EN 61508 (BSI 2002) and related international standards provide the guidance needed to evaluate and con rm the dependability of a system that has a safety function. As a result, a powerful tool has been added to the safety toolbox and its use ensures a safer offshore working environment. That is of course, as long as it is aired outside of the toolbox!
Detection and control systems are part of normal operational requirements for retaining quality as well as ensuring safety with pressure, temperature and volume levels being monitored and corrected on a frequent/ continuous basis; should these be compromised, a dangerous situation could evolve. On a less frequent, through to “once-in-a-blue-moon” basis, detecting abnormal excursions that need prioritised actions to prevent dangerous scenarios is equally important. Each case has a different operational signature and it is important to understand how frequently equipment or system failure could lead to an accident:
If there is a frequent drift from the ideal that needs to be controlled, the accident rate approximates to the failure rate, λ which is the reciprocal of the Mean Time to Failure (MTTF).
Where demand is low, the accident rate is a combination of how often there is a trigger and the chances that that it will not be detected i.e. the PFD, which is the reciprocal of the Risk Reduction Factor (RRF).
Introducing preventive maintenance, by proof testing the system more frequently than when it is called upon to react (proof test interval T), the relationship can be defined as:
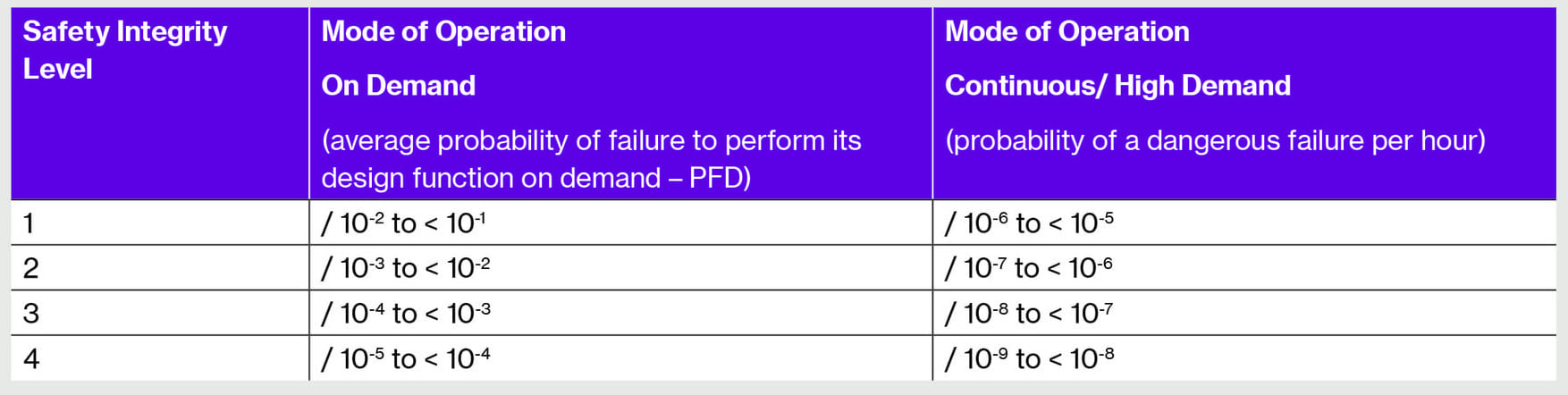
Referring to BS EN 61508, (which will be the subject of a future article), Safety Integrity Levels are assigned against failure probabilities for low and continuous demands as per the table below:
When determining whether a SIL 1, SIL 2, or SIL 3 system is needed, the first step is to conduct a Process Hazard Analysis to determine the functional safety need and identify the tolerable risk level. After risk reduction and mitigation from the process control system and other layers of protection are taken into account, this leaves the residual risk, which is compared with the stated risk tolerance. If these do not match, risk reduction is needed and the SIL requirement is calculated.
It should be noted that the SIL requirement applies to a complete function, i.e. the eld sensor, the logic solver and not just the nal element. Care needs to be taken when referring to the HSL data quoted, but the PFD for the RESDVs appears to be around 3 x 10-2, which complies with SIL 1 without considering the associated system elements. Current good practice suggests that RESDV systems should be rated as SIL 2.
Current good practice for topside valves e.g. Emergency Shutdown Valves (ESDVs) On/O Valves (XV) and Blowdown Valves (BDVs), suggests an annual full stroke functional test, taking into consideration that such valves self-proof-test through, occasionally trip and have partial stroke testing as part of their maintenance programmes.
It should be noted that some operators are reluctant to undertake a full RESDV test regime that requires valve closure (to check internal leakage) since this may affect well-stability and recovery following the testing process. Feeder platforms routing liquids for further treatment or relaying gas for further compression/ transport onshore can also suffer control problems depending on hold-up potential, time and distance.
The good news is that unplanned valve closures happen and the results of these are often recorded within Distributed Control Systems (DCS). It is important that this information is captured and credited within the maintenance records.
Neil Stairmand is a graduate chartered mechanical engineer responsible for conducting risk control surveys and providing an engineering service to Willis Towers Watson clients.